

Picture this: It’s 8:00 AM on a weekday. A bustling coffee shop is the go-to spot for caffeine seekers before work. A long line snakes through the shop as customers wait for their lattes and espressos. There’s just one barista at the counter, working frantically to fulfill orders. The result? A growing line, stressed customers, and a barista overwhelmed by the sheer volume of work.
Now imagine the shop employs a smarter strategy. Instead of relying on one baristas counter, they have three counters, each staffed by skilled baristas. As customers enter, a host directs them to the counter with the shortest queue. Suddenly, the line moves faster, customers are served more quickly, and everyone gets their coffee without unnecessary delays. This coffee shop’s solution is a perfect analogy for load balancing in system design.
Introduction to Load Balancing
In system design, load balancing refers to distributing incoming requests or workloads across multiple servers or resources to ensure no single server becomes overwhelmed. It’s like the host at the coffee shop directing customers to different counters, ensuring smooth operations.
Without load balancing, systems can quickly become bottlenecks. Imagine the chaos of a busy coffee shop with only one barista—orders would take forever, customers might leave, and the barista would be overworked. Similarly, without load balancers, servers can crash under heavy traffic, leading to downtime and frustrated users. By spreading requests across resources intelligently, load balancers maintain system stability, improve performance, and enhance user experience.
In this blog, I am going to discuss about few important features of load balancing which coffee shop example, which are mentioned below.
- Load Balancing Algorithms
- Load Balancing Types
- Scalability and Performance
- Stateless vs. Stateful Load Balancing
- Challenges of Load Balancing
Load Balancing Algorithms
Load balancing algorithms determine how traffic (or customers, in our coffee shop analogy) is distributed across available resources. These algorithms ensure that tasks are handled efficiently and equitably to optimize performance and user experience. Let’s explore the most common load-balancing algorithms through coffee shop scenarios and their tech equivalents.
- Round Robin
- Weighted Round Robin
- Least Connections
- IP Hash
- Random
- Least Response Time
- Geolocation-Based Routing
- Dynamic Weighted Algorithms
- Custom Algorithms
Let’s understand these algorithms in detail.
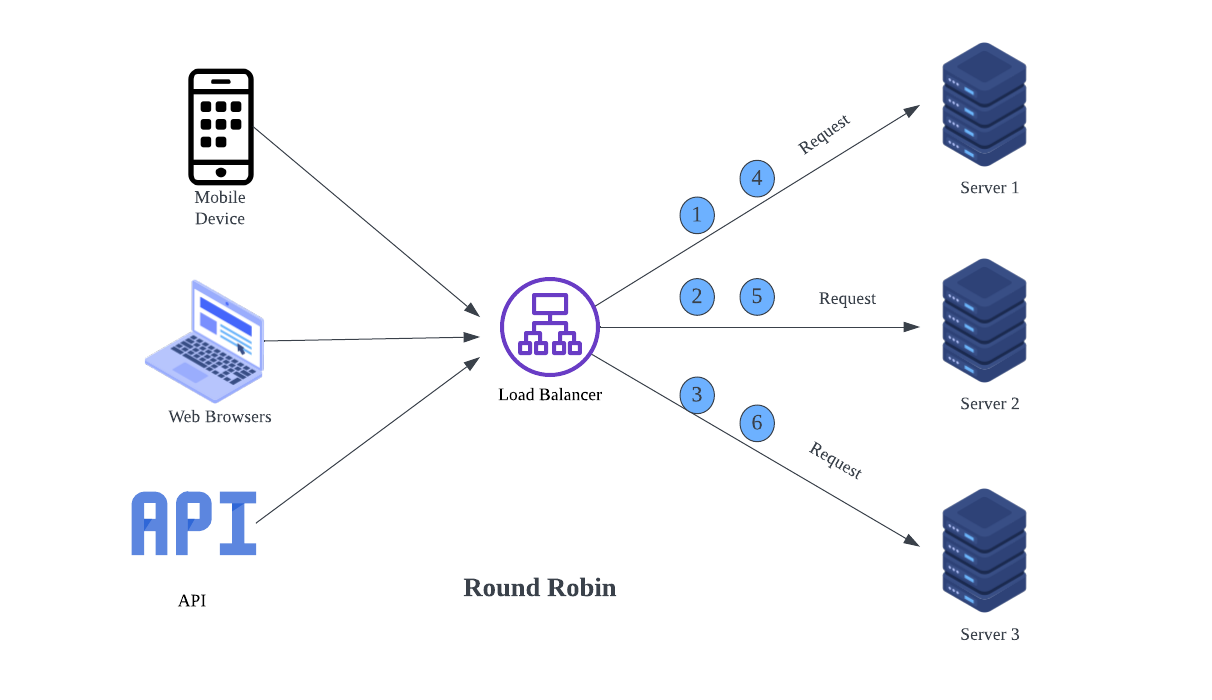
Round Robin
Imagine a host at the coffee shop who sends each customer to the next barista in line. If there are three baristas, the first customer goes to Barista 1, the second to Barista 2, the third to Barista 3, and the cycle repeats. Round Robin is one of the simplest load-balancing algorithms. It assigns incoming requests to servers in a sequential, circular order. It works well when all servers have equal capacity and the workload is evenly distributed. For example, A content management system serving static web pages can use Round Robin to distribute requests among identical servers efficiently.
Weighted Round Robin
If Barista 1 is faster and can handle two customers for every one customer served by Barista 2 or 3, the host assigns two customers to Barista 1 for every one sent to the others. Similarly, Weighted Round Robin builds on the Round Robin algorithm by considering the capacity of each server. Servers with higher weights receive more requests. It’s useful when servers have varying performance capabilities.

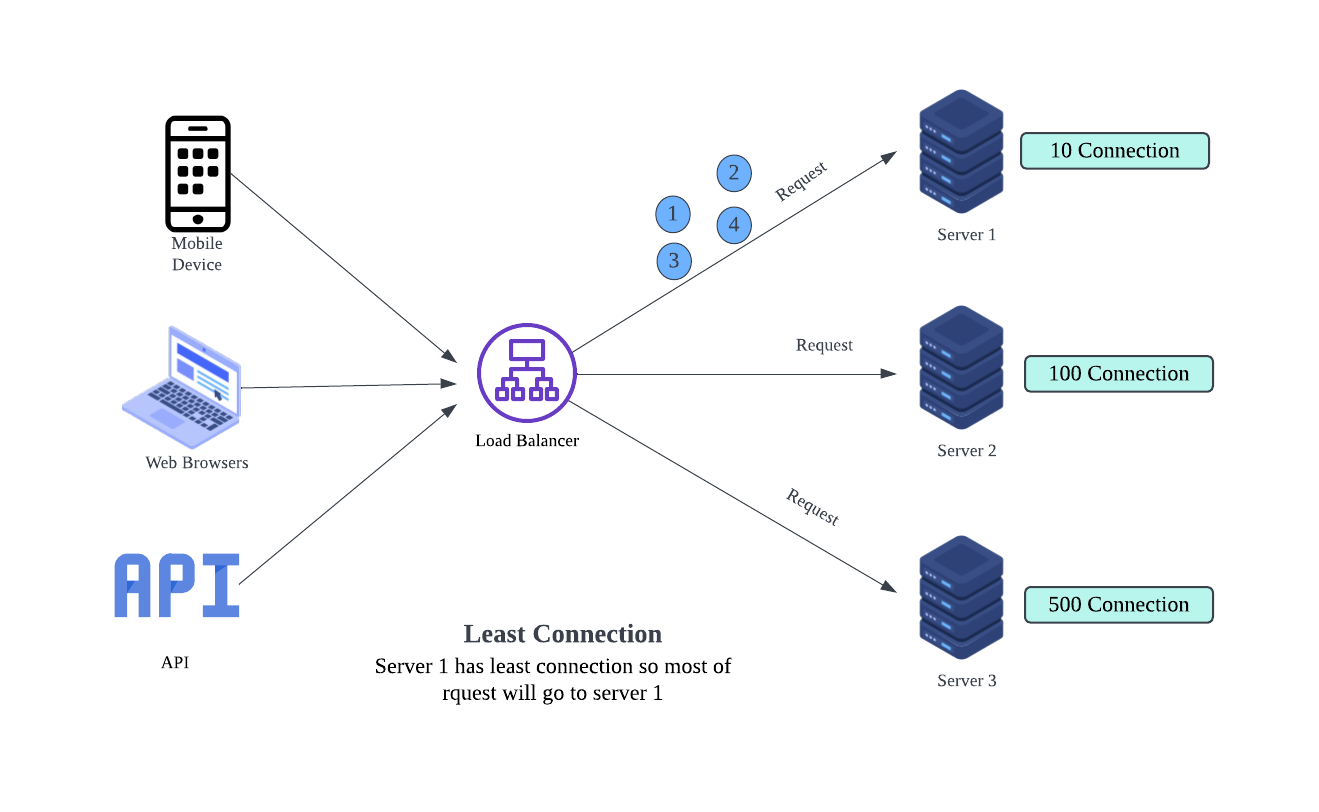
Least Connections
In a coffee shop, the host keeps track of how many customers each barista is currently serving. New customers are directed to the barista with the fewest active orders, ensuring that no one is overwhelmed. Similarly, the Least Connections algorithm sends traffic to the server with the fewest active connections. It’s particularly effective for applications where tasks require different processing times, as it prevents slower servers from becoming bottlenecks.
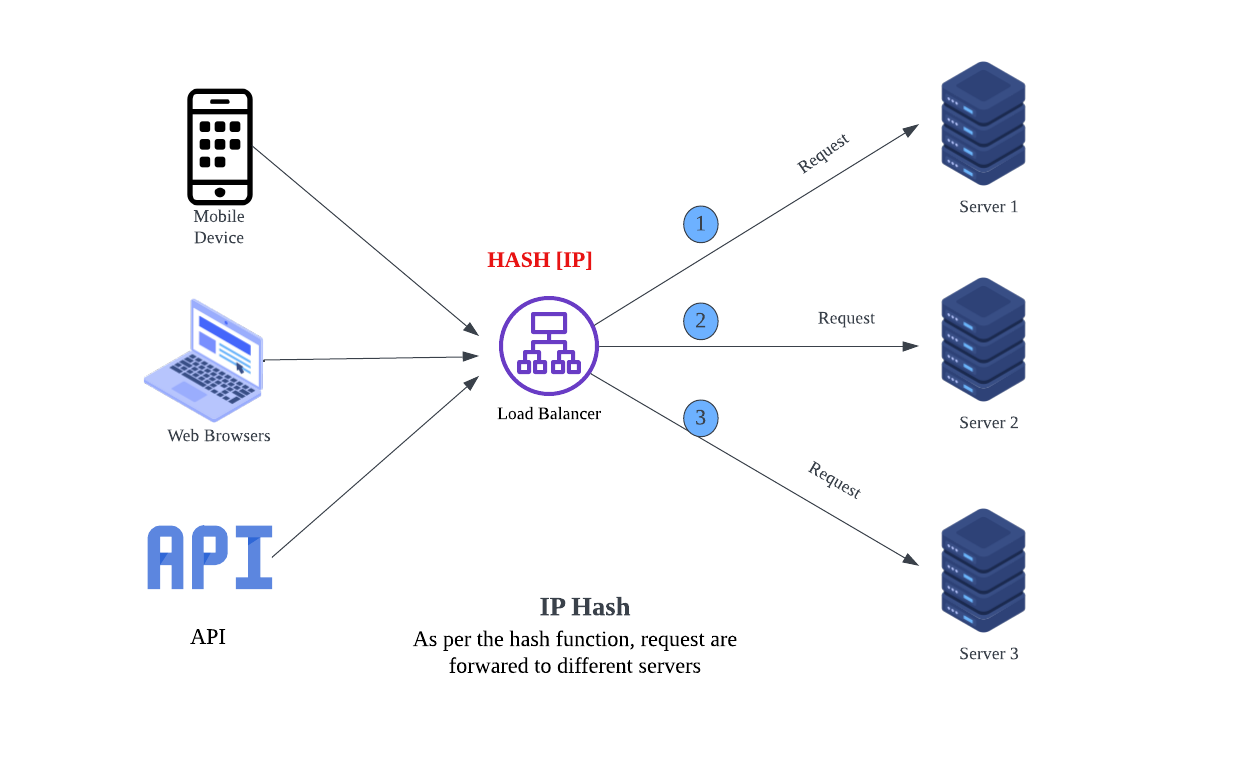
IP Hash
Imagine the coffee shop assigns customers to baristas based on their last name. Customers with last names starting from A-M go to Barista 1, and N-Z to Barista 2. Once assigned, they always go to the same barista for consistent service. Similarly, IP Hash uses a hashing function on the client’s IP address to determine which server handles the request. This ensures that a client is always directed to the same server, which is useful for session persistence.
Random
The host simply points customers to baristas at random, without considering their workload or past assignments. Similarly, the Random algorithm selects a server at random to handle each incoming request. While simple, it can lead to uneven load distribution if servers vary significantly in capacity or the workload is unpredictable.

Least Response Time
The host monitors how quickly each barista completes their orders. Customers are sent to the barista with the shortest queue and the fastest average service time. Similarly, Least Response Time routes traffic to the server with the shortest active queue and the lowest response time. This is ideal for real-time systems where latency directly impacts user experience.
Geolocation-Based Routing
In a coffee shop example, the coffee chain has branches in multiple neighborhoods. Customers are directed to the branch closest to their location for faster service and fresher coffee. Similarly, This algorithm routes traffic based on the client’s geographic location. It minimizes latency and improves performance by sending users to servers in nearby data centers. Global applications like Spotify use geolocation-based load balancing to serve users from the closest data center.
Dynamic Weighted Algorithms
In a coffee shop example,the host constantly monitors baristas’ energy levels and efficiency throughout the day. If one barista slows down after a long shift, their workload is reduced, and more customers are sent to other baristas. Similarly, Dynamic Weighted Algorithms adjust server weights in real time based on performance metrics like CPU usage, memory availability, and response time. It ensures adaptive traffic distribution in changing conditions. Cloud-native systems with auto-scaling capabilities use dynamic algorithms to allocate traffic based on current resource availability.
Custom Algorithms
The host creates a custom rule: regular customers are assigned to their favorite barista, while new customers are assigned randomly. This ensures a mix of efficiency and personalization. Organizations can design custom algorithms tailored to their unique requirements, such as prioritizing premium users or routing traffic based on application-level data. Streaming services like YouTube may use custom algorithms to prioritize content delivery for premium subscribers.
Load Balancing Types
- Hardware Load Balancer
- Software Load Balancer
- Cloud Load Balancer
- Global Load Balancer
- Network Load Balancer (Layer 4)
- Application Load Balancer (Layer 7)
- Hybrid Load Balancer
Let’s understand these types in detail.
Hardware Load Balancer
A physical device dedicated to load balancing, designed to handle high volumes of traffic with specialized hardware. Hardware load balancers operate at high speeds and are often deployed in on-premises data centers. This type is suitable for enterprises requiring low-latency, high-performance solutions with strict security or compliance needs. Example: F5 BIG-IP, Citrix ADC
Software Load Balancer
A load-balancing solution that runs as software on general-purpose hardware or virtual machines. These are highly configurable and cost-effective. It is ideal for businesses using standard servers or virtualized environments, especially in cloud-native or containerized applications. Example: NGINX, HAProxy, Apache Traffic Server
Cloud Load Balancer
A managed load balancing service provided by cloud platforms. Cloud load balancers are fully integrated with cloud ecosystems and can automatically scale to handle traffic. It is best for organizations running applications in public cloud environments. Example: AWS Elastic Load Balancer, Azure Load Balancer, Google Cloud Load Balancer
Global Load Balancer
A load balancer that routes traffic across servers located in different geographic regions. It helps reduce latency by directing users to the nearest data center. It is Essential for applications with a global user base, such as content delivery networks (CDNs) or international e-commerce platforms. Example: Cloudflare Load Balancer, AWS Global Accelerator.
Network Load Balancer (Layer 4)
Operates at the transport layer (Layer 4) of the OSI model, distributing traffic based on IP address, TCP/UDP ports, or protocol. It provides ultra-fast routing and handles high volumes of raw network traffic. It is used for applications requiring extremely low latency, such as financial trading systems or gaming servers. Example: AWS Network Load Balancer.
Application Load Balancer (Layer 7)
Operates at the application layer (Layer 7) of the OSI model, routing traffic based on content such as HTTP headers, URLs, or cookies. Ideal for web applications and APIs. It is suitable for modern applications requiring smart traffic distribution and features like SSL termination or session persistence. Example: AWS Application Load Balancer, HAProxy (configured for Layer 7).
Hybrid Load Balancer
Combines multiple load-balancing strategies, often blending Layer 4 and Layer 7 capabilities. Hybrid load balancers can distribute traffic based on both network and application-layer information. It is ideal for complex applications that require flexibility and scalability, such as hybrid cloud environments or large-scale enterprise solutions. Example: A hybrid solution combining AWS NLB (Layer 4) and ALB (Layer 7).
Scalability
In the coffee shop example, the shop has two baristas serving customers. As the line grows, the shop hires additional baristas and opens new counters to handle the increasing demand. Once the rush subsides, the shop reduces the staff and closes extra counters to save resources.
Scalability refers to a system’s ability to handle an increasing number of requests by adding resources (e.g., servers, processors). There are two types of scalability.
- Vertical Scalability (Scaling Up): Adding more powerful machines to handle increased demand.
- Horizontal Scalability (Scaling Out): Adding more servers to distribute the workload.
E-commerce platforms like Amazon use horizontal scalability during peak shopping seasons like Black Friday to add servers dynamically as user traffic spikes.
Performance
The coffee shop’s performance depends on how quickly baristas can prepare orders and serve customers. If a barista is slow or inefficient, the line grows longer, and customer satisfaction drops.
In system design, performance measures how efficiently a system handles user requests, usually assessed by metrics like latency, throughput, and response time.
For digital systems, scalability and performance must work hand in hand. For example, a video conferencing platform like Zoom may add servers (scalability) during a major event but also optimize data compression algorithms (performance) to reduce bandwidth usage and ensure smooth streaming
Stateless vs. Stateful Load Balancing
Stateless: Load balancing can be stateless or stateful, depending on whether the load balancer keeps track of previous interactions. Lets understand with coffee shop example.
In a stateless coffee shop, the host does not remember any customer’s previous interactions. When a customer enters, they are directed to any available barista, even if they’ve already placed part of their order with another barista. This may lead to confusion if the baristas aren’t aware of previous parts of the order.
In stateless load balancing, the load balancer does not retain any knowledge about prior requests. Each incoming request is treated independently and routed to any available server based on the load-balancing algorithm (e.g., Round Robin or Least Connections).
Stateful: In a stateful coffee shop, the host remembers every customer. For example, if a customer orders a sandwich at Counter 1 and later wants coffee, the host ensures they go back to the same counter to maintain continuity. The barista at Counter 1 knows their order history and can serve them efficiently without starting over.
Stateful load balancing tracks the state of each client-server interaction. The load balancer ensures that all requests from the same client are routed to the same server. This is critical for applications where session data (e.g., user login or shopping cart) must persist across multiple requests.
Challenges of Load Balancers
- Overhead in Load Balancing
- Single Point of Failure
- Session Persistence Challenges
- Uneven Load Distribution
- Scalability Limitations
- Security Vulnerabilities
- Latency in Multi-Region Deployments
- Monitoring and Maintenance
Let’s understand these challenges in detail.
Overhead in Load Balancing: Load balancers introduce additional latency because every request must pass through them before reaching the server. This is particularly problematic in high-performance systems where even milliseconds of delay can impact user experience. Use efficient load-balancing algorithms to minimize decision-making overhead.
Single Point of Failure: If a load balancer fails and no redundancy is in place, the entire system can become unavailable. This is a critical risk in high-availability systems. The solution is to Implement high availability with multiple load balancers in active-active or active-passive configurations
Session Persistence Challenges: Some applications require session persistence to ensure that all requests from the same client go to the same server. Maintaining this consistency can be challenging in horizontally scaled systems, especially if a server fails or traffic is rerouted. Use techniques like sticky sessions or token-based session persistence to solve this problem.
Uneven Load Distribution: Load balancers can fail to distribute traffic evenly if they’re not configured properly or if the workload is unpredictable. This can cause some servers to be overwhelmed while others are underutilized. Use advanced algorithms like Weighted Least Connections or Dynamic Load Balancing to account for server capacity and current load.
Scalability Limitations:Load balancers themselves can become a bottleneck in large-scale systems, especially during rapid traffic spikes. Vertical scaling (adding more resources to the load balancer) has limits, and horizontal scaling (adding more load balancers) introduces complexity. Use a hierarchical load-balancing architecture where multiple load balancers distribute traffic collaboratively
Security Vulnerabilities: Load balancers are often targets for attacks like DDoS (Distributed Denial-of-Service) or man-in-the-middle attacks. A compromised load balancer can expose the entire system to security risks. Use security features like SSL/TLS termination, firewalls, and DDoS protection.
Latency in Multi-Region Deployments: In globally distributed systems, a load balancer may need to route traffic to servers across multiple regions. Latency can increase significantly if the load balancer isn’t optimized for geographic routing. Use geolocation-based routing to direct users to the nearest servers.
Monitoring and Maintenance: Load balancers require continuous monitoring to detect and respond to issues like server overloads or outages. Lack of visibility into load balancer performance can lead to undetected bottlenecks. Use monitoring tools like Prometheus, Grafana, or cloud-native monitoring solutions to track load balancer metrics. Set up alerts for anomalies and regularly review performance logs
Conclusion
In conclusion, load balancing is more than just a technical tool—it’s a fundamental enabler of the digital experiences we rely on daily. From preventing downtime to scaling businesses globally, load balancers are at the heart of modern system design. By mastering its concepts, you can build systems that are robust, scalable, and ready to handle the demands of tomorrow.